Optimization Techniques for Spring Data JPA Traps
Step-by-step cases and solutions

Introduction
Spring Data JPA improves the implementation of JPA-based repositories. Such a module is related to extended support for JPA-based data access layers. It makes building applications that use Spring-powered data access technologies much easier.
Thus, the goal of Spring Data JPA is to significantly enhance the implementation process of data access layers through reducing the effort to the amount really needed.
In our short guideline, we will show the optimization cases of specific examples without unnecessarily long descriptions. You will also be provided with the scripts with the given solutions for discussed framework/library. The simpler, the better.
ProcessPlaylist Method
- The case: unwanted changes saved in DB
The main task of the ProcessPlaylist method is to extract data from the request and save them in the database. It is possible that something bad and unexpected happens before the method ends. What should be done in such a case? Do we want to have some data saved in the DB? In most cases, the answer is NO. There is no guarantee that the data is consistent. All changes to the DB should be rollbacked.

Fix: trigger rollback with Transactional annotation
One of the easiest ways to add rollback support for a failed flow is the Transactional annotation. For each exception thrown, all DB changes made to the method will be rolled back. This is the default behavior. The Transactional annotation has many properties, including propagation, isolation, timeout, rollbackFor. There are many options for configuring DB transactions.

- The case: “safe” change with side effects
It is not always easy to find an error related to the DB operation. In this case, one action (addSongs) was moved after calling saveAll. Existing tests will still pass (unit tests, functional tests, regression tests, e2e), as there is no change in the application’s behavior. We are not aware of anything wrong that could happen.

Action: activate SQL logging
To be able to see the generated SQL queries you need to add new entries in the configuration. This should be activated only in the development environment. In production, this is not needed.
The generated queries are now visible in the logs. The number of queries and their correctness can be verified.

Fix: call addSongs() before saveAll()
Adding SQL logging helped us find a performance problem (an additional UPDATE statement for each track). This example was trivial. In more complex code, it is difficult to see these types of problems without SQL logging.

Operations performed on the target object are propagated to the related object
In some cases, we want a tighter connection between entities. Adding a cascade parameter in the OneToMany annotation can help with this. Operations performed on the target entity are propagated to the associated entity. Fewer repository calls are needed to achieve the same result. The risk of forgetting to update or delete a related entity is reduced.
In this example, the save method is called only on the playlist entity. By using cascading, the songs will also be saved.

- The case: multiple UPDATE DB calls for a simple task
Very often we don’t think about performance when we add new functionality to an application. If you are a Java programmer, you want to write code in Java. This is generally fine, but in some cases moving easy-to-implement business logic to SQL may be worth considering.
In the updateSongs method presented, a new UPDATE statement will be executed for each song.

Fix: use SQL/JPQL for simple task
The same functionality can be achieved with a simple SQL/JPQL query. The code is still quite easy to understand and has better performance. Only one UPDATE statement will be generated here.

- The case: h2 in memory DB has better performance
All the previously presented Postman calls had very low execution times. The main reason for this is the use of the h2 database. It is an In-Memory database, so the latency is lower. To see how the disk database behaves, we switched to Oracle DB.

Fix: activate hibernate batching
A significant increase in productivity can be achieved by enabling hibernate batching. The batch size parameter may not be so easy to estimate. You need some information about the size of the data being processed. The Generate_statistics property can help analyze performance for different batch sizes.

- The case: additional SELECT for each Playlist
The N+1 query problem occurs when the data access framework makes N additional SQL calls to fetch the same data that could have been retrieved when the main SQL query was executed.
In the current configuration, the findAllSongs method would generate one SELECT query to get all the playlists and N additional SELECTS to get the songs for each playlist found.
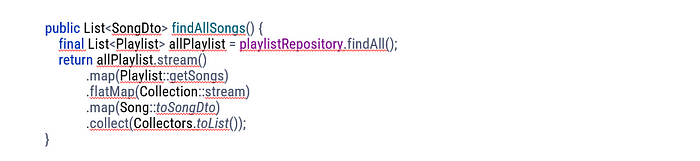
Fix: add Fetch annotation
Adding the Fetch annotation is a quick solution to the “N + 1” problem. It’s not perfect because 2 SELECT statements will be generated to get all the pieces, but it’s still better than N + 1.
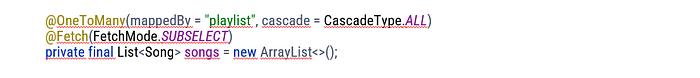
Summary
So that’s it. We collected the cases with suggestions for fixing them. If you have any experience with the Spring Data JPA library, it would be nice if you share in the comments! Please visit our blog, where there is not only a lot about programming, but also a lot of other technical and IT-related topics. Something new again soon!
The material was created in collaboration between Senior Engineer — Dariusz Tomczyk (Altimetrik Poland) and Content Writer — Kinga Kuśnierz (Altimetrik Poland) based on materials from a webinar Dariusz recently hosted.
